Benson Duong
Data Science major at UC San Diego
Interests in Data Science, Python Programming, Machine Learning.
Sub-Project 1: Predicting How a User Rates a Restaurant Rating Based on Their Review
- For this 1st task, I created a machine learning prediction model that determines whether a user’s rating for a restaurant is negative or not, given the text of their review.
Data Preparation
-
The main idea of the data preparation is that it finds a set of keywords whose presence (or absence) in a given user’s review for a restaurant will determine how the user rates it. For this prediction model, the plan is to look for the keywords that are “bad”, and their presence indicates a negative rating, while their absense might indicate a positive rating.
-
But Python has no clue which keywords are “bad” or however deemed by humans. To find said “negative” keywords, I took a large set of reviews, and separated them into 2 groups in terms of having high vs low ratings. The ratings are from 1 (bad) to 5 (good). I decided that anything below 5 was “bad”. The reason being was noticing that restaurant-goers tend to over-give 5-star ratings leniently.
-
Then I employed TF-IDF, a data mining method for words that is supposed to find the most “distinctive” group-wise keywords of either of these 2 groups (keywords that show up more often within a group, compared to outside that group). This is resting on the expectation the most “distinctive keywords” of the bad-ratings group is mostly going to be “emotionally negative” words.
Model
- For machine learning, scikit-learn was used, and the technique used would be logistic regression
- The prepared data however, faced the issue of class imbalance; This was resolved with undersampling.
Evaluation
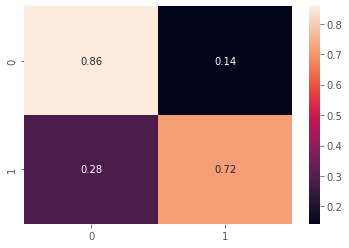
- The results on the test data showed that this prediction had a remarkable accuracy in determining if a user would rate a restaurant as good or bad based on their text review;
- This metrics table means that out of the times where a user rates the restaurant positively, it is able to correctly predict that the rating was positive 86% of the time, based on the user’s review; out of the times where a user rates the restaurant negatively, it is able to correctly predict that the rating was negative 86% of the time, based on the user’s review;
- Finally, a peek at the 20 most influential keywords to appear in a google review, in determining if a user will give a restaurant a bad rating.
- This is actually the absolute values of the model’s coefficients, since each word’s presense is a feature of the logistic regression.
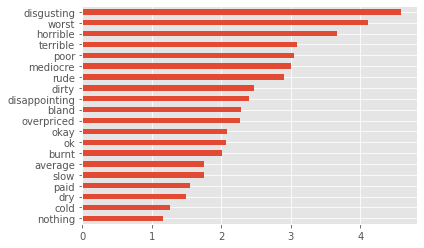
- This makes sense, as most of these words have negative connotations, and even more impressively, it manages to pick out words that aren’t just negative, “emotional” words (like worst, or bland)- it also includes words that are otherwise arguably neutral but deemed negative in the context of food or a restaurant (dry, cold). It doesn’t even need to be related to food, but the service itself (slow, rude).